
ChatGPT, yazılı içerik oluşturmayı normalde olabileceğinden çok daha kolay hale getirdiğinden beri, bir dizi yapay zeka içerik algılayıcısı ortaya çıktı. Birçoğu bu dedektörleri kullanmaya başladı. Çünkü bu durum, yapay zeka tarafından oluşturulan içeriği tespit etme potansiyeline sahip olabilecek türdedir.
İçerik algılayıcılar ne kadar etkilidir? Southern Methodist Üniversitesi Bilgisayar Bilimleri Bölümü tarafından yürütülen bir çalışma bu sorulara yanıt bulmaya çalıştı. Detaylar haberimizde...
İlginizi Çekebilir: Volkswagen Araçlarına ChatGPT Geliyor! İşte Detaylar
Çalışmanın Detayları
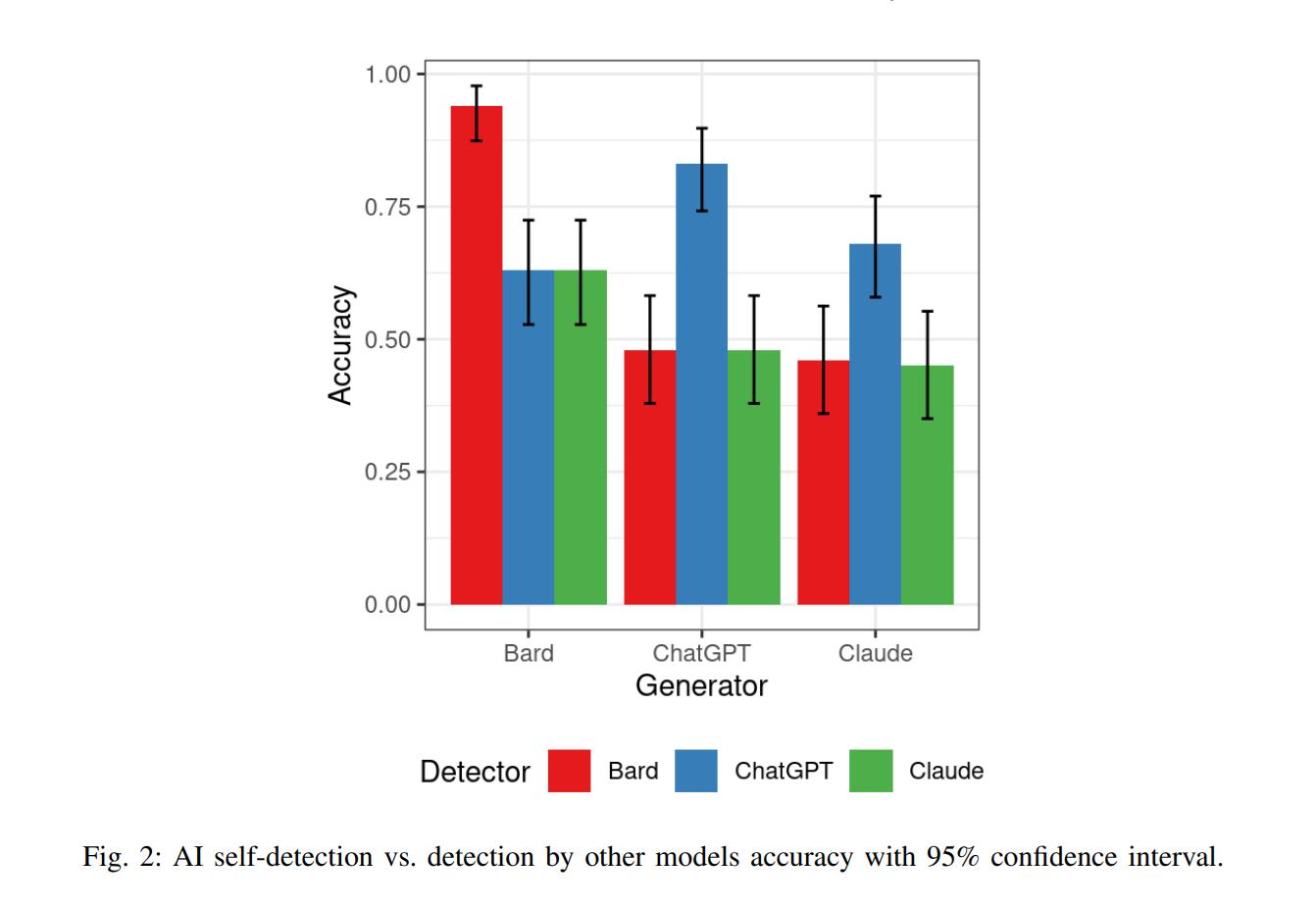
Araştırmacılar hangilerinin tespit edilmesinin daha kolay olduğunu belirlemek için Claude, Bard ve ChatGPT'yi analiz etti. Bütün bunlar söylenmiş ve artık bir kenara bırakılmışken, Claude'un aslında çoğunlukla tespit edilmekten kaçan içerik sağladığını not etmek önemlidir. ChatGPT ve Bard ise kendi içeriklerini tespit etme konusunda daha iyiydi. Ancak üçüncü taraf araçların tespitini engelleme konusunda Claude kadar iyi değillerdi.
Yapay zeka içerik algılayıcılarının çalışma şekli, yapay unsurları aramaları veya başka bir deyişle, bir içerik parçasının büyük dil modelleri kullanılarak oluşturulduğunun işaretlerini aramalarıdır. Her LLM, kendine özgü bir dizi eserle birlikte geliyor. Bunların tümü, her şeyin dikkate alındığı durumlarda, bunların tam olarak belirlenmesinin az çok zorlayıcı olmasına katkıda bulunabilir.
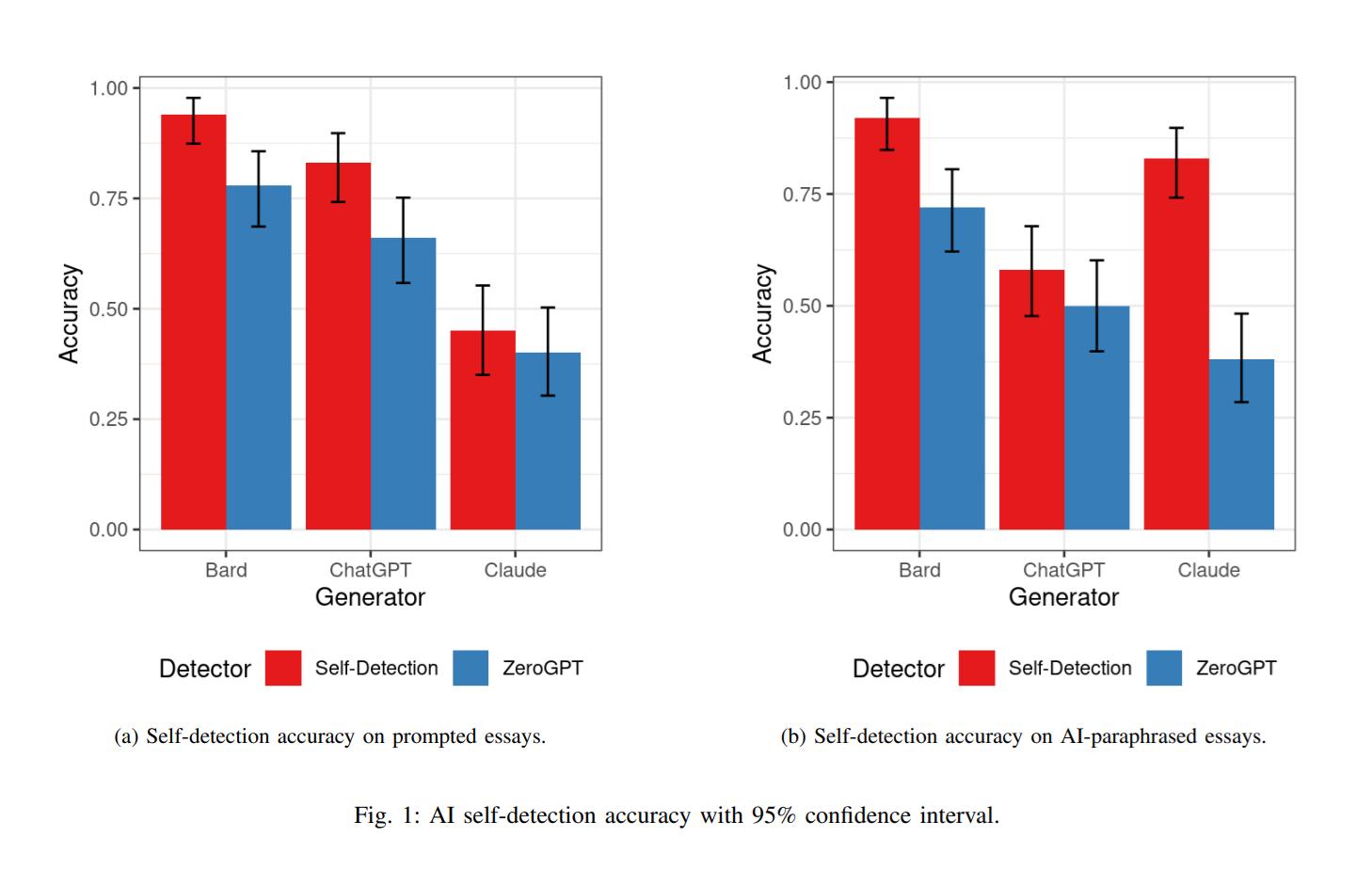
Bu çalışmanın yürütülme şekli, yaklaşık 50 konu için 250 kelimelik bir içerik oluşturulmasını içeriyordu. Daha sonra analiz edilen üç yapay zeka modelinden bu içeriği yeniden ifade etmeleri istendi. İnsanlar tarafından da üretilen elli makale de denklemin içine dahil edildi.
Sıfır atış yönlendirmesi daha sonra bu yapay zeka modelleri tarafından kendi kendini algılama amacıyla kullanıldı. Kendi içeriğini tespit etmede en yüksek doğruluk düzeyine Bard sahip olurken, onu ChatGPT ve Claude son sırada izledi.
Open AI tarafından sunulan bir AI içerik dedektörü olan ZeroGPT ise Bard içeriğini yaklaşık yüzde 75 oranında tespit etti. GPT tarafından oluşturulan içeriği tespit etmede biraz daha az etkiliydi. Claude, tüm modeller arasında çoğu kez içeriğin yapay zeka tarafından oluşturulmadığına inandırarak onu kandırmayı başardı.
Burada belirtilmesi gereken bir şey de belirtelim ki, ChatGPT'nin kendi kendini algılama oranının yüzde 50 civarında seyretmesidir. Bu, bu çalışma bağlamında bir başarısızlık olarak değerlendirilen tahmin etmeyle aynı doğruluk oranına sahip olduğunu gösteriyor gibi görünüyor. Başka kelimelerle ifade edilen içeriğin kendi kendine tespiti daha da ilginç sonuçlar verdi. Claude çok daha yüksek bir kendini tespit puanı kaydetti. ZeroGPT tarafından tespit edildiğinde de en düşük doğruluk puanına da sahipti.
Claude Yalnızca Diğer Yapay Zeka Modellerini Değil Aynı Zamanda Kendi Tespitini de Alt Etmeyi Başardı
Sonunda araştırmacılar için ekleyelim. ChatGPT'nin oluşturmak için kullanıldığı içeriği tespit edebildiği ancak başka kelimelerle ifade edilen içeriği kaydetmede daha az etkili olduğu sonucuna vardı. Bard her iki durumda da oldukça iyi performans göstermeyi başardı. Ancak bu modellerin her biri Claude tarafından çok geride bırakıldı.
Claude yalnızca diğer yapay zeka modellerini değil, aynı zamanda kendi tespitini de alt etmeyi başardı. Bu, içeriğin kökenini belirlemek için kullanılabilecek en az yapıya sahip olduğunu gösteriyor gibi görünüyor. Daha fazla kanıt elde etmek için daha fazla çalışmaya ihtiyaç olacak. Ancak işaretler Claude'un en güvenilir metin oluşturucu olduğunu gösteriyor.




Bu habere henüz yorum yazılmamış, haydi ilk yorumu siz bırakın!...